
GeoHash空间索引算法简述
背景
在空间索引类问题当中,一个最普遍而又最重要的问题是:”给定你某个点的坐标,你如何能够在海量的数据点中找到他所在的区域以及最靠近他的点”?
最常见的应用就像是**POI(Point of Interest)**的查询了,比方说客户在路上突然想吃饭了,那么我就要根据他的位置查询最近的餐馆并根据这个做出推荐。
通常情况下,一提到查找类问题,我们就会想到二分查找或者是B树查找。但是问题在于我们不仅要找到这个点,而且要找到这个点附近的点。因此对于以经纬度来确定的坐标又不好直接进行二分查找。(如果是直接用数据库索引的话,由于数据库通常是B树索引和Hash索引,因此查找效率并没有提高。)
通常情况下我们会用R树、Kd树或者是四叉树之类的数据结构来存储这些点从而高效的做到临近点的查找。但是这些数据结构通常都会存在数据冗余,以及不稳定的查改效率;况且抛开他们的时间效率、空间效率以及算法复杂度不谈,用了这些数据结构也就意味这我们放弃了使用现成强大的数据库而自己编写数据查改系统,这显然是繁琐而又没有必要的过程。而且当系统需要扩展到分布式计算的时候就更不如使用那些分布式的数据库了。
这时我们就会想到,如果能够把一个二维的信息转化为一维的数据加以存储,那么我们不就可以直接存储到数据库中做到快速的查找了么?
GeoHash做的就是这个工作。
简述
GeoHash是由Gustavo Niemeyer(大概于2013年)提出的,目的原本是为地球上的每一个点(根据经纬度)确定一条短的URL作为唯一标识。只是后来被广泛的应用到空间检索方面、尤其是之前提到的POI查询中。这个服务一直在http://geohash.org上,上面还有一些具体的介绍。
GeoHash所做的事就是把一个坐标点映射到一个字符串上,每一个字符串代表的就是一个以经纬度划分的矩形区域。比方下面的图就展现了北京地区所在的九个区域,分别是WX4ER、WX4G2等等。
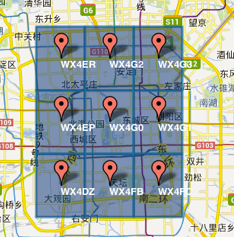
于此同时,每一个区域又可以继续划分为许多个小区域,如下图所示,WX4G0就包含了WX4G09、WX4G0C、WX4G08等等。而且每一个子区域的GeoHash值都是在父区域后面拓展一个字符。
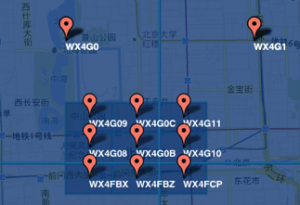
这样就形成了一个层次分明的结构,越高级的区域GeoHash值越短,表示的区域最大;越小的区域GeoHash值越长,表示的区域越小。
算法
定位算法:
事实上GeoHash算法也十分简单,根据上面的意义我们很容易想到他用的是类似四叉树的方法来寻找一个点;换句话说就是不停的在经度和纬度上进行二分类,最终确定到想要的精度,划分的过程下图所示。

交替在两个方向进行分割,一个区域计为0,一个区域记为1,并将结果追加在父区域GeoHash值的后面。不断的进行划分直到得到了想要的深度。对于每一个区域最后会得到一个二进制的字符串,然后每5位为一组,用0-9 b-z(去掉a, i, l, o)进行Base32编码即可得到该区域经过编码后的GeoHash值。当然,编码这个步骤只是为了让结果看上去变短而已,实际应用中可以把它变成一个二进制数(由于存在前导0,所以要在最前面加一个1),当然直接用字符串的形式也未尝不可。
有一个小细节,就是区域之间会有边界,那么边界上的点属于哪里呢?我的处理是所有的区域都只是包含经度和纬度方向上的左闭右开区间。
邻居查找算法:
如果想要查找某个点附近的Top m个临近点,我们显然不会直接扫描地图中所有的点(这样效率会极其低下),而是用上面的定位算法,将该点定位到一个比较小的区域里(这个区域里有n个临近点,且n>m),然后再扫描这个较小区域里的所有点,用自己定义的权重公式,取出最符合的点。这个方法一般叫做**“Filter and Refine”**方法,即”先过滤,后提纯“。
既然如此,通过上面的**定位算法,**我们可以将这个点定位到一个比较小的区域里,然后查找该区域的所有点即可。不过问题来了,由于GeoHash编码并不能保证查询的点是在他所在区域的中心,这就导致了下图中的问题:

显然,红色的点属于最中间的区域,直接查找该区域会得到他下方的绿色点是最接近的点。但是由于这个点比较靠近区域的边界,事实上更接近的点却是位于他上方的相邻格子的绿色的点。因此我们并不能仅仅查找他当前区域内的所有点,而是要查找以该区域为中心的九个区域范围。(当然这样也有可能存在着查找错误的问题,但是可能性就大大降低了)。
随便在网上找了下,没有找到比较方便的查找邻居的算法(当然预处理保存的除外),于是我就想了一个朴素简单的方法:我们可以在定位某点的时候,记录下该点所在区域的经纬度范围,然后只要取出这个区域外的八个点,然后对这八个点分别跑八次定位算法就可以求出他附近的所有区域了。
临近点的查找策略:
由于GeoHash对一个坐标点的编码可以有不同的深度(精度),因此在临近点的查找中也就存在了层次的选择策略。我们显然不能一概而论的将每个点都查找到相同的层次,否则要么由于精度太高而找不到临近点,要么由于精度太低而找到太多的临近点。我的策略是:
- 首先确定一个最高的精度,我们认为在这个精度下的所有区域中的点都是极少的;
- 然后确定一个期望的临近点个数k;
- 对于某个坐标点,计算出在最高精度下的区域时由邻居查找算法得到的临近点的个数b。
- 如果b小于k,那么就把精度提高一层(即将其GeoHash编码末尾的几个字符删除)继续执行邻居查找算法直到找到的临近点的个数大于等于k;
- 用邻居查找算法查询当前精度下的所有临近点并将其作为”Filter”后的候选集供后续的**“Refine”。**
- 注意到这个参数k非常重要,当他的值小的时候算法的准确率会下降,但是效率会提高;反之准确率会提高,效率会下降。因此,当我们期望的运行时间一定时,我们可以通过用启发式的方法,根据期望运行的时间、路径中点的个数等因素调节参数k,从而达到效率和准确率的最佳平衡。
精度
最初Gustavo Niemeyer在定义GeoHash编码的时候是以全球的坐标作为总的区域来分的,因此他计算出了不同编码长度的GeoHash区域对应的范围。不过我们平常自己写的时候并不需要覆盖全球的所有地区,而且也不必用Base32来编码。如果非得那拿全球作为总的区域来划分,那么我们可以很容易的计算出来只要最多在经度和纬度上分别划分24次左右就可以使最小的区块达到1m的精度。在没有缓存的情况下也只要循环二十几次就可以定位到需要的区域,效率还是很高的。
与R树的比较
一、稳定性:GeoHash编码与数据集的大小无关,因此对于任意大的数据集,他的定位和查找效率都非常高(常数时间);而R树在建树时需要花费至少$O(nlogN)$的复杂度(事实上为了保持树的平衡还会花费更多的时间),况且R树家族的数据结构基本都会存在区域重叠,当数据量大的时候无论是建树还是查找都会很费时。
二、拓展性:GeoHash可以与当前的任何一种数据库管理系统结合使用,不仅可以享受数据库的优化,而且还可以利用NoSQL数据库非常轻松的实现分布式存储和查找;R树则一般是在内存中进行查找,虽然现今大多数数据库也有空间索引的引擎,但是标准不统一,性能也不是很稳定,而且大规模批量插入数据时性能也不理想。