
LLT工作总结与Gherkin语法解析器简单应用
前言
这几天产品线这里要搞LLT(Low level Test)重点工作,保障版本的高质量发布。工作当然包括一系列的规范、培训、编码、检视,不过具体看下来主要还是提取了下面的一些度量要点:
- 保证LLT运行不挂(废话)
- 清零无效LLT代码
- 保证LLT对代码的覆盖率
- 保证LLT对需求的覆盖率
清零无效LLT代码,意思是指通过一些检查工具,检查出LLT代码中没有使用断言的测试,或者是那种假装使用了断言的测试代码("assert(true);")。显然,这两种情况下写的LLT代码永远无法告警,因此是没有任何意义的。
保证LLT对代码的覆盖率很简单,就是通过测量测试代码对业务代码的覆盖率,保证软件的质量。虽然代码覆盖率并不能够绝对代表测试的充分程度,但是在排除恶意提高覆盖率的情况下,也可以作为度量LLT代码质量的一个参考。
保证LLT对需求的覆盖率这一点是一个比较小众的概念,这主要是对BDD(Behaviour Driven Development)实践执行效果的一个辅助度量方式。我们知道BDD的要点在于将功能需求作为测试的方案,测试代码围绕着需求展开(而不是函数)。这样一方面写完测试代码就相当于写完了测试文档,任何人都可以非常清晰的理解LLT代码的实际目的是什么;另一方面也可以很好的从需求的层面保障新需求经过了完备的LLT测试。那么为了度量LLT对需求的保障程度,就需要将需求进行编号,然后与LLT对应,以度量需求的覆盖率以及需求的平均用例数。
吐槽
LLT的初衷是将代码错误拦截在软件生命周期的较早的阶段,减少后期处理bug的代价。但是,凡事都是要辩证的来看,既然LLT跟BDD的好处有点那么多,为什么不是所有的产品都采用了这一套流程呢?显然,这样的一套流程不可避免的会带来很多额外的工作量,软件度量这件事情本身就是值得商榷的,如果不采用硬性的指标规定,管理者无法切实有效的进行管理,开发人员也没有动力去遵守;而采用硬性的指标规定,又势必容易导致一刀切,而事实上很多指标在某些情况下没有达成的必要,如果偏要达成,则容易造成很大的资源浪费。
我在推进这项工作的时候也经常发现下面这些远离我们初衷的现象:
- 写LLT代码本身也容易引起额外的bug,增加了整体代码的维护难度。
- 对“无效LLT代码”的定位不准,容易造成诊断错误,简单的检查工具无法识别特殊场景下的确有用的LLT代码。
- 有时候纯粹是为了覆盖率而“补”用例,用例本身并不能测出漏洞反而浪费时间。
- 很多需求本身不涉及LLT代码(比如涉及配置或者一些静态文件需求),这样的话统计LLT对需求的覆盖率这件事本身可能就没有什么实际意义。
- 很多时候当LLT代码量庞大时,会极大地延长代码的编译构建时间,拖慢项目进度。
其实LLT的根本目的就是为了节约成本,节约时间(提前发现问题,减少回溯成本),可如果一味地为了做好LLT而投入了过多的时间和成本,那我觉得可能就是有点舍本逐末了。
不过谁在乎呢?公司舍得花钱,领导需要政绩,码农需要活干,那就干呗。
工作
我这边的具体工作大概就是写一个扫描Cucumber测试文件的检查工具,并且对接公司内部的需求设计平台,统计出LLT代码与需求的关联度并做可视化展示。这个工作的难点大概就是解析Cucumber文件了。Cucumber大概是当前比较流行的BDD框架了,虽然这个东西并不是很新,但是当前很多大型软件公司也在用。这个东西的好处自不必说,网上的各种推荐跟教程都有很多。不过作为一个靠谱的码农不在迫不得已的情况下还是尽量不要学二手的知识比较好,而且要尽量保持视野的开阔,能不造轮子就不造轮子。这不,仔细研究一下就知道,Cucumber用例文件的语法解析器什么的都是开源的,代码下下来捣鼓捣鼓就好了,完全没有必要自己从0开始造轮子。
Gherkin语法
Cucumber工具采用的他自己定义的语法---Gherkin。这个其实很简单,官网上解释的很详细。比如下面的文件就描述了两个测试场景。
Feature:
Scenario Outline:
Given <x>
Examples:
| x |
| y |
Scenario :
Given XXXYYYZZZ
And QQQWWWEEE
Then AAABBBCCC
那我们怎么将他跟需求对应起来呢?
我们在需求设计和分析阶段的时候会把用户需求进行逐步细分和下发。一个典型的例子就是从用户描述的初始需求,拆分为工程领域的系统需求,再细分到各个子模块,由具体开发人员当成一个个小的用户故事来开发。到了这一层面,每一个需求就会对应一个需求单号,我们就通过这个来需求进行识别。
有了需求单号,我们就可以通过在Cucumber工具定义的feature文件里以标签的形式加进来:
@ST.SR.IR.XXX.YYY.ZZZ
Feature:
@ST.SR.IR.AAA.BBB.CCC
Scenario Outline:
Given <x>
Examples:
| x |
| y |
gherkin语法支持在多个地方添加@标签。这个标签本来是用作“开关”,方便程序员在执行时选择执行,不过我们现在拿来对接需求单号也未尝不可,毕竟每一个用例都可以对应多个标签,二者互不影响。
文件解析
下面就牵涉到具体的文件解析,我们需要从feature文件里提取出标签,并对应上他所标注的用例。
Gherkin本身提供了将文件解析成抽象语法树(AST)以及JSON(Pickle)的功能,AST本身功能强大,但是稍微复杂一点,JSON更好理解,而且一般来说解析成类似下面的JSON也就够用了。
{
"type": "pickle",
"uri": "testdata/good/readme_example.feature",
"pickle": {
"name": "",
"steps": [
{
"text": "y",
"arguments": [],
"locations": [
{
"line": 9,
"column": 7
},
{
"line": 5,
"column": 11
}
]
}
],
"tags": [
{
"name": "@a",
"location": {
"line": 1,
"column": 1
}
},
{
"name": "@b",
"location": {
"line": 3,
"column": 3
}
},
{
"name": "@c",
"location": {
"line": 3,
"column": 6
}
}
],
"locations": [
{
"line": 9,
"column": 7
},
{
"line": 4,
"column": 3
}
]
}
}
可以看到,每一组用例就是一个pickle,里面清晰的表明了Cucumber语句的位置,标签,路径等等信息。
官网文档中写的不是很详细,毕竟给Cucumber做二次开发的人也不多。文档中给了各个语言
的底层接口,不过比较简略,用起来也不是很方便。于是我就看了下CLI工具的实现,用JAVA简单摸索了一下。
具体实现
首先是安装依赖,我习惯用maven,最新的版本号可以参考这里的,不过我当前用的是一个稍老的稳定版本:
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>gherkin</artifactId>
<version>5.0.0</version>
</dependency>
测试用feature文件:
@a
Feature:
@b @c
Scenario Outline:
Given <x>
Examples:
| x |
| y |
@d @e
Scenario Outline:
Given <m>
@f
Examples:
| m |
| n |
读取feature文件并解析:
public class Main {
public static void main(String[] argv) throws IOException {
Path self = Paths.get("/home/myths/Desktop/Test/");
List<String> pathList = Files.walk(self)
.map(Path::toString)
.filter(name -> name.endsWith(".feature"))
.collect(Collectors.toList());
Gson gson = new GsonBuilder().create();
SourceEvents sourceEvents = new SourceEvents(pathList);
GherkinEvents gherkinEvents = new GherkinEvents(false, false, true);
List<PickleEvent> pickleEventList = new ArrayList<>();
sourceEvents.forEach(sourceEvent -> gherkinEvents.iterable(sourceEvent).forEach(x -> pickleEventList.add((PickleEvent) x)));
pickleEventList.forEach(pickleEvent -> {
System.out.println(gson.toJson(pickleEvent.pickle.getTags()));
});
}
}
主要是下面的步骤:
- 读取代码文件。
- 扫描出feature文件。
- 创建SourceEvents,其实就是feature文件的集合。
- 创建GherkinEvents,其实是选择解析的模式,是否包含源码,是否包含AST树,是否包含Pickle,我们当然只选择Pickle。
- 用GherkinEvents去遍历SourceEvents获得PickleEvents,其实到这一层就已经解析到了每一组用例了。
- 最后选择需要显示的信息即可。Gherkin默认采用Gson来处理JSON数据。
输出结果样例:
[{"location":{"line":1,"column":1},"name":"@a"},{"location":{"line":3,"column":3},"name":"@b"},{"location":{"line":3,"column":6},"name":"@c"}]
[{"location":{"line":1,"column":1},"name":"@a"},{"location":{"line":11,"column":3},"name":"@d"},{"location":{"line":11,"column":6},"name":"@e"},{"location":{"line":15,"column":3},"name":"@f"}]
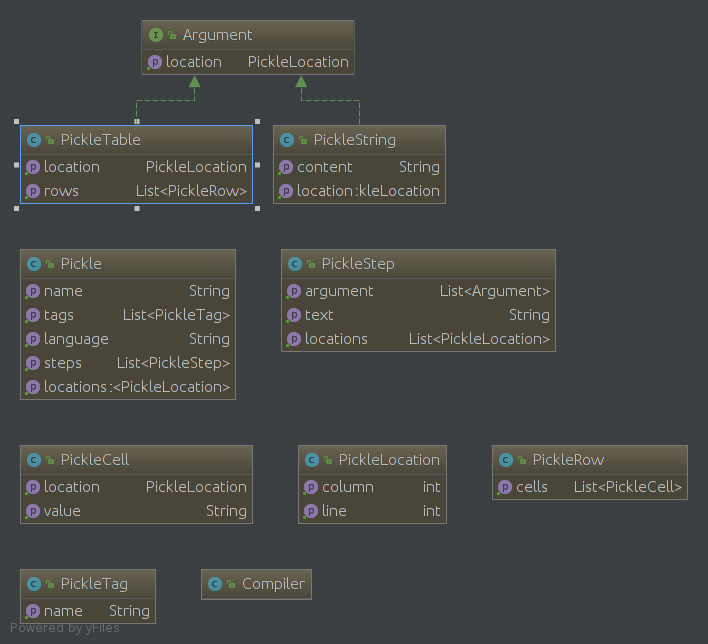
围绕生成Pickle类的关键类图如下:
有了这套流程,我们就可以很方便的获得每组用例所对应的标签,然后加以统计分析了。