
Linux-C简单多线程编程分析
我们都知道多线程可以提高程序运行的速度,但是至于能够提高多少却一直没有一个直观的印象,下面就用Linux C的多线程编程技术,简要分析下多线程的运行效率。
测试代码
下面就用1000*1000的矩阵之间的乘法来做一个实验,我们分别用单线程和多线程分别实现,算法都采用$O(n^3)$的朴素算法。测试代码如下:
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <sys/time.h>
#define LEN 1000
#define MAXNUM 1000
#define MAXTHREADNUM 16
long long matrix1[LEN][LEN]={0};
long long matrix2[LEN][LEN]={0};
long long sum[MAXTHREADNUM]={0};
long long ans=0;
long long getCurrentTime(){
struct timeval tv;
gettimeofday(&tv,NULL);
return tv.tv\_sec * 1000 + tv.tv\_usec / 1000;
}
void genMatrix(char *file){
FILE *fp=fopen(file,"w");
srand(time(NULL));
for(int i=0;i<LEN;i++){
for(int j=0;j<LEN;j++){
int random=rand()%MAXNUM;
fprintf(fp,"\t%d",random);
}
fprintf(fp,"\n");
}
fclose(fp);
}
void getMatrix(long long matrix[LEN][LEN],char *file){
FILE *fp=fopen(file,"r");
for(int i=0;i<LEN;i++){
for(int j=0;j<LEN;j++){
fscanf(fp,"\t%lld",&matrix[i][j]);
}
char tmp;
fscanf(fp,"%c",&tmp);
}
fclose(fp);
}
int threadNum;
void* runner(void *p){
int pid=*(int*)p;
long long sumT=0;
for(int i=pid;i<LEN;i+=threadNum){
for(int j=0;j<LEN;j++){
for(int k=0;k<LEN;k++){
sumT+=matrix1[i][k]*matrix2[k][j];
}
}
}
sum[pid]=sumT;
free((int *)p);
pthread_exit(NULL);
}
void multiThread(int num){
threadNum=num;
long long clock1=clock();
long long time1=getCurrentTime();
pthread_t id[MAXTHREADNUM];
for(int i=0;i<threadNum;i++){
int *p=(int *)malloc(sizeof(int));
*p=i;
pthread_create(&id[i],NULL,runner,p);
}
ans=0;
for(int i=0;i<threadNum;i++){
pthread_join(id[i],NULL);
ans+=sum[i];
}
long long clock2=clock();
long long time2=getCurrentTime();
printf("Multi Thread %d:\n",num);
printf("Ans =\t%lld\nClock time =\t%lldms\nUnix time =\t%lldms\n\n",ans,(clock2-clock1)/1000,time2-time1);
}
int main(){
char name1[50]="matrix1.txt";
char name2[50]="matrix2.txt";
FILE *fp=fopen(name1,"r");
if(fp==NULL){
genMatrix(name1);
}else{
fclose(fp);
}
fp=fopen(name2,"r");
if(fp==NULL){
genMatrix(name2);
}else{
fclose(fp);
}
getMatrix(matrix1,name1);
getMatrix(matrix2,name2);
for(int i=1;i<=16;i++){
multiThread(i);
}
}
程序简要分析
注:为了方便验证结果的正确性,我计算了$\sum x_{ij}$来进行对比。
单线程的部分自不必说,多线程的部分我采用的并不是通用的线程池,也不是对每一个任务都创建一个线程,而是根据行数模线程数的值来分配给不同的线程。这样总线程数一直不变,相对简化了线程创建的开销,以及代码量。
关于pthread库的使用也是很讲究的。
对于pthread_create 来说,为了保证能够兼容不同的回调函数,他在创建进程的时候将回调函数的参数和返回值都定义为void*。那么如果想传入自己的参数就要用一个指针来传入数据并强制转换为void *,然后在回调函数里强制类型转换为实际的类型。如果要传入多个参数,就要自己写一个结构体来传,还是非常麻烦的。而且这里还要注意一点,就是不能把临时变量的引用当做参数传给回调函数,因为临时变量是会在循环结束后立即被释放的,这样会导致回调函数得不到正确的值。正确的做法应该是malloc一块内存,并用指针把这块内存传给回调函数,回调函数在执行完任务逻辑后再自行释放。
对于pthread_exit 和pthread_join 来说,我们要知道的是,pthread_exit才是真正传递回调函数返回值的地方。我们将需要返回的值传递给他,然后再用pthread_join 的第二个参数来接受这个参数。不过通常为了简单起见都会开一个全局数组来接受不同线程的计算结果。
当然,多线程最怕的就是不同线程对同一数据的修改,如果必须修改,那么就得对这块代码块加锁。
关于程序的逻辑,我们需要注意的就是计算结果可能会过大导致数据溢出,因此我们要小心控制下数据的大小。
还有一个小细节,就是如何用Linux C来获取Unix 时间戳,一开始以为是clock()函数,不过后来才发现,clock()函数是cpu时间,不是真正的时间。比如说我的cpu有四个核,这四个核同时工作了1s,那么用clock()函数做差可以发现结果是接近4s。因此,正确的做法是重写一个getCurrentTime函数,这样就能得到真正的Unix时间戳。
最后需要注意的就是程序在编译时需要加上-lpthread 参数。
运行结果分析
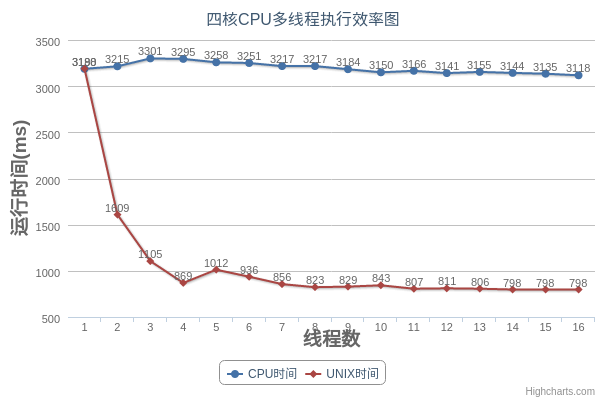
对于一个四核的电脑,我们运行的结果是:
对于一个九十六核的服务器,我们运行的结果是:
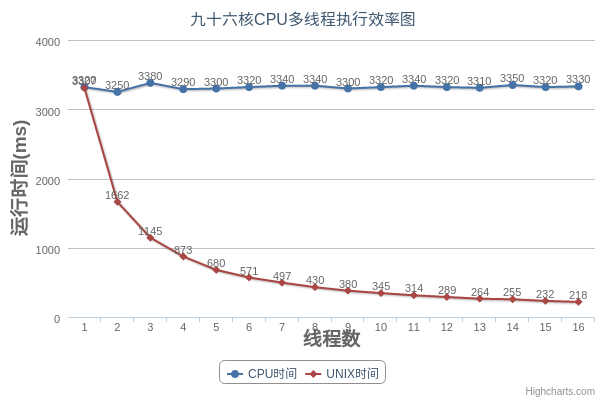
我们可以发现,对于九十六核的服务器而言,UNIX时间*线程数近似等于CPU时间,而CPU时间近似保持不变,多线程的特性发挥的很完美。而对于四核的电脑来说,当线程数大于四的时候,我们就发现程序的执行时间就开始发生波动,执行效率并没有随着线程数增加而有所提高。