
路径匹配之距离归并MD算法简析
简述
距离归并算法(Merge Distance)也是一种计算路径相似度的算法(其实“路径归并”是我自己瞎翻译的,因为没有找到更加官方的中文翻译)。跟DTW,LCSS之类不同,他提出来时间不算长,但是思想也是十分简单的。计算方便理解容易,也是进行路径相似度匹配的不错的思路。
问题描述
MD算法解决的问题是,给定两个序列$(A_1,A_2,A_3,A_4...A_n)$和$(B_1,B_2,B_3,B_4...B_m)$,其中每一个元素可以都可以是一个二维坐标点或者是更高维度的坐标。现在我们需要找到一条路径,使他经过这两个序列的所有点,且保证若$i < j$那么$A_j$一定在$A_i$后面出现(对于$B$亦然)。显然这样我们可以有多种结果,那么我们只要取最短的那个路径来作为最后能够代表他们相似度的路径。具体要求如下图所示:
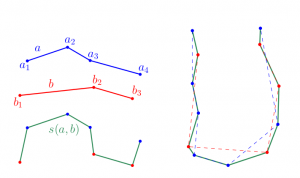
对于左边的图,下面的那个路径就是对上面的路径进行归并后的最短路径;对于右边的图,绿色的实线路径就是对蓝色和红色的虚线路径归并后的最短路径。
Merge Distance算法就是为了求出这个最短的路径长度。
算法
简单dp。
对于序列$A[1:n],B[1:m]$,令$MDa[i][j]$表示以$A[i]$为终点的序列$A[1:i]$和$B[1:j]$所形成的最短路径的长度;令$MDb[i][j]$表示以$B[j]$为终点的序列$A[1:i]$和$B[1:j]$所形成的最短路径的长度;$dis(X,Y)$表示$X$和$Y$之间的距离。这样我们就可以构造如下的递推关系式:
$i=1:$
$$MDa[i][j]=dis(A[i],B[j])+\sum_{k=2}^{j}dis(B[k-1],B[k])$$
$j=1:$
$$MDb[i][j]=dis(A[i],B[j])+\sum_{k=2}^{i}dis(A[k-1],A[k])$$
$for\ 1< i\leq n,1\leq j \leq m:$
$$MDa[i][j]=min\left\{\begin{matrix}MDa[i-1][j]+dis(A[i-1],A[i])\\MDb[i-1][j]+dis(A[i],B[j])\end{matrix}\right.$$
$for\ 1\leq i\leq n,1< j \leq m:$
$$MDb[i][j]=min\left\{\begin{matrix}MDa[i][j-1]+dis(A[i],B[j])\\MDb[i][j-1]+dis(B[j-1],B[j])\end{matrix}\right.$$
这样我们就可以很容易的求出$MDa[n][m]$和$MDb[n][m]$,然后取其中的较小值作为最终的长度。复杂度$O(m*n)$
后续处理
通过上面的算法我们算出了两个序列归并后的路径长度记为$L(A,B)$,同时我们把路径$A$的长度记为$L(A)$,路径$B$的长度记为$L(B)$。当两个路径完全重合的时候,很明显这个值会等于$L(A)\ or\ L(B)$。显然,如果我们想把$L(A,B)$作为路径相异度的量度的话,最好还是让他此时的值等于零。因此我们会对他的值进行一下处理,使他更像一个相似度的量度而不仅仅是一种距离。我们如下定义这个量度$MD(A,B)$:
$$MD(A,B)=\frac{2*L(A,B)}{L(A)+L(B)}-1$$
这样,我们所定义的这个值就满足路径完全相同时,相异度就是0,而且这个值并不会随着路径长度的增加而丧失准确度。
总结
Merge Distance算法所得到的量度对于原路径点与**降采样(SubSampling)后的路径点或超采样(SuperSampling)**后的路径点的相异度评判差别很小(论文中实验为证),这也是相对于传统的DTW,欧氏距离等相似度评判方法表现突出的地方。
参考
Anas Ismail,Antoine Vigneron.A New Trajectory Similarity Measure for GPS Data, (KAUST) Thuwal 23955-6900, Saudi Arabia