Python多核编程分析
简述
之前一直都用python的多线程库(比如threading)来写一些并发的代码,后来发现其实用这个方法写的程序其实并不是真正的并行(parrallel)计算,而只是利用单个CPU进行的并发(concurrency)计算。因此,多线程也仅仅只在处理一些被频繁阻塞的程序时才会有效率上的提升,比如网络爬虫里等待http返回等;而在CPU使用密集的程序里使用多线程反而会造成效率的下降。那么为什么python不把threading库设计成并发的线程呢?这是因为python本身有一个全局翻译锁,叫GIL(Global Interpreter Lock),这个锁的目的是让当前的python解释器在同一时间只能执行一条语句,从而保证程序的正确运行,这也就导致了一个python解释器只能并发处理而不能并行处理。那么,如果想并行的执行代码,显然需要开启多个python解释器,这也就不是多线程,而是多进程了,因此python在多线程库里并不支持多核处理,而是在多进程库(multiprocessing)里支持多核处理。
多线程编程:
多线程编程比较简单,主要利用threading类即可:
import threading
mutex = threading.Lock()
def little_thread(arg):
print 'Thread %d start.'%(arg)
mutex.acquire()
#critical area
mutex.release()
while True:
arg*=arg
def test():
threads=[]
thread_num=4
for i in range(thread_num):
t=threading.Thread(target=little_thread,args=(i,))
t.start()
threads.append(t)
for t in threads:
t.join()
if __name__=='__main__':
test()
基本用法也就是把执行逻辑的函数传给Thread对象,并用tuple的形式传进参数,然后start就可以开始线程,最后join阻塞等待线程结束。
同时,也可以自定义锁,来保护共享数据或者临界区。
这里注意到我在死循环里写的不是空语句,而是一个较为复杂的计算,这是因为如果写的不是空语句,那么操作系统可能会对线程进行优化,导致效果不理想。
我把上面的代码运行在一个四核的机器上,用htop工具查看各个cpu的占用情况:
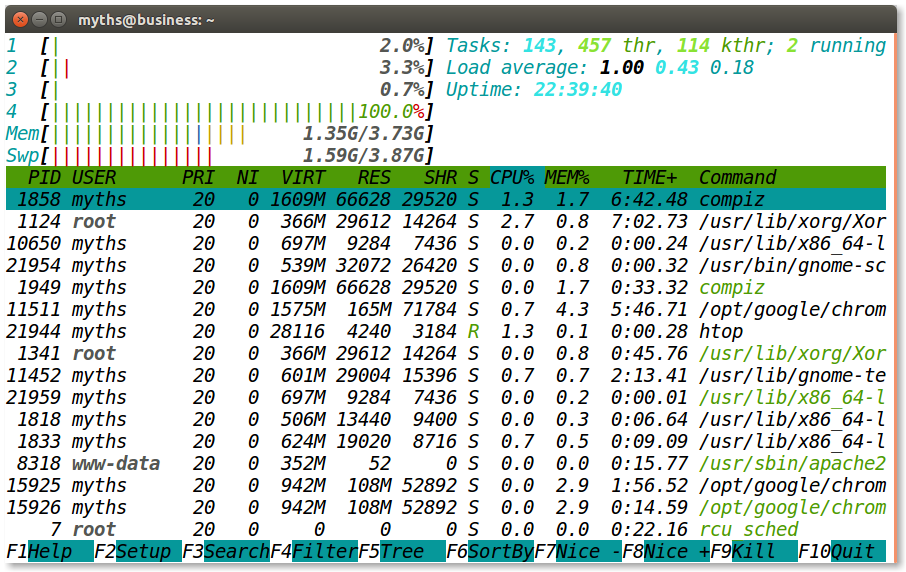
我们发现这四个核基本只有一个核在全速运行,其他的三个核基本没有工作,这就说明了多线程其实并没有真正用到多个核。
多进程编程
多进程编程方法其实和多线程类似,只是需要注意多进程的各个子进程无法直接访问父进程内的公共变量(毕竟已经是一个独立的进程了,有自己的数据段)。为了解决这个问题,就需要用到一个Manager来管理共享变量:
import multiprocessing
#shared variable
output_line=multiprocessing.Manager().list()
def little_process(arg):
print 'Process %d start.'%(arg)
output_line.append(arg)
while True:
pass
def test():
processes=[]
process_num=4
for i in range(process_num):
t=multiprocessing.Process(target=little_process,args=(i,))
t.start()
processes.append(t)
for t in processes:
t.join()
if __name__=='__main__':
test()
这段代码跑出来的CPU使用率是这样的:
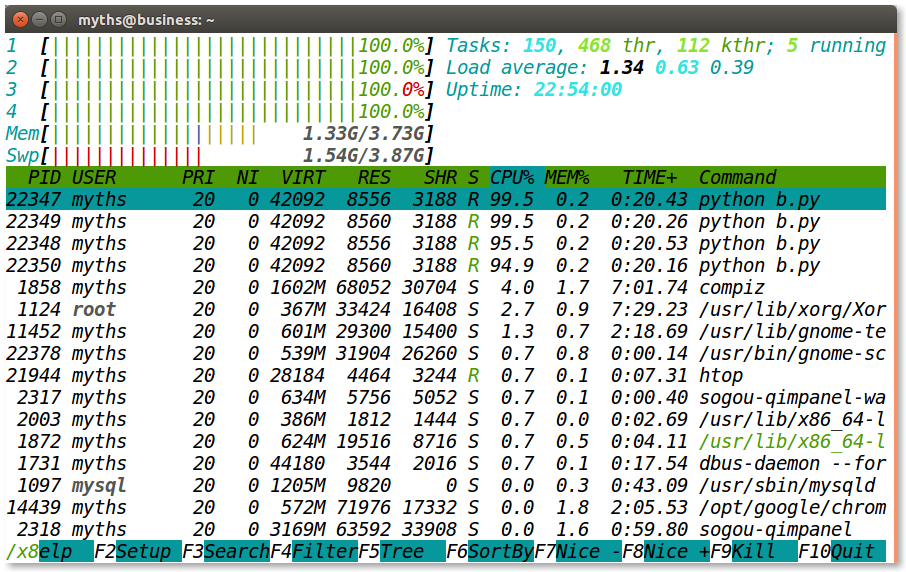
显然,多进程充分发挥了多核计算机的有点,对CPU密集型的程序有着极好的加速效果。
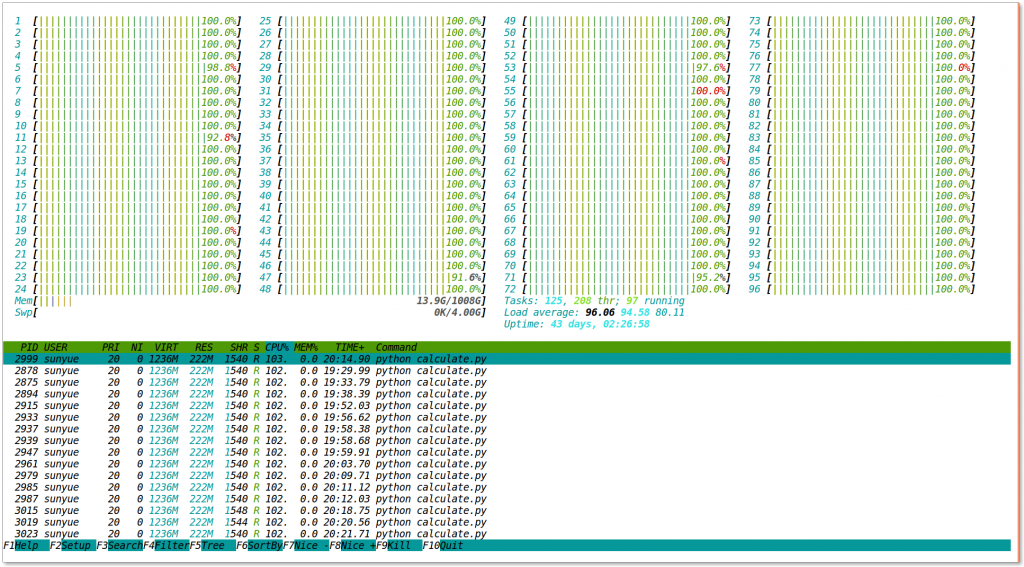
附一张爽歪歪的图(话说实验室的服务器用起来还是挺爽的):