
•
 by mythsman
by mythsman
Python读取mnist数据集
在看deeplearning教程的时候遇到了这么个玩意,mnist,一个手写数字的数据集。大概是google为了方便广大程序员进行数字识别而构建的库,里面都是美国中学生手写的阿拉伯数字,但是为了方便存储,他并不是以图片的形式保存的,而是以二进制文件的形式保存的。这就让普通人看着略微蛋疼的了,教程里也并没有提供具体的提取图片的方案。得,读取这个还得自己来。
地址
我用的应该是用python处理过的版本: mnist.pkl.gz,这个好像是为了方便用python读取特意配置过的。
分析
别看他是压缩文件,解压之后并没有用,而是一个很大的文本文件,还得在这里读取。文档里说,这里面有60000个训练图片,10000个测试图片,训练图片又分为了train_set 和valid_set两个集合(不懂是啥意思)。每个集合内都包含了图片和标签两块内容,图片都是28*28的点阵图;而标签,则是0-9之间的一个数字。
说的也挺清楚的,思路也大概晓得了,我们当前的任务应该就是用matplot进行绘图保存即可。
代码
折腾许久也是弄好了,教程中说要用theano来存图,然而theano还不会用。。。0.0
import cPickle, gzip
import numpy as np
import matplotlib.pyplot as plt
def display(data):#显示图片
x=np.arange(0,28)
y=np.arange(0,28)
X,Y=np.meshgrid(x,y)
plt.imshow(data.reshape(28,28),interpolation='nearest', cmap='bone')
plt.colorbar()
plt.show()
return
def save(data,name):#保存图片
x=np.arange(0,28)
y=np.arange(0,28)
X,Y=np.meshgrid(x,y)
plt.imshow(data.reshape(28,28),interpolation='nearest', cmap='bone')
plt.savefig(name)
return
f = gzip.open('mnist.pkl.gz', 'rb')#读取数据
train_set, valid_set, test_set = cPickle.load(f)#分类
f.close()
train_set_image,train_set_num=train_set
token=10 #需要显示的图片个数
for i in range(0,token):
save(train_set_image[i],"./"+str(i)+"-"+str(train_set_num[i]))
我显示了10张图片,打开第一张(0-5.png)看看效果:
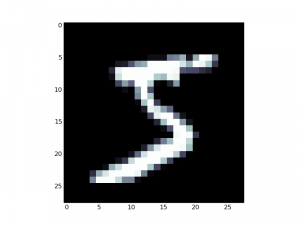
这就是美国人写的5。。。