
•
 by mythsman
by mythsman
自适应阈值分割的Bersen算法
最近处理到游侠网的验证码,学习了一点东西,聊作记录。
游侠网的验证码总体来讲比较简单,字符分割比较清楚。稍微有难度的地方就是处理他的阴影。
** 示例 **


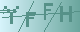

很明显,如果直接拿这种图去跑机器学习算法的话肯定准确率不高,必然需要进行灰度或者二值化。当然,二值化是比较好的选择。
但是由于灰度分布是不均匀的,如果采用类似OTSU的全局阈值显然会造成分割不准,而局部阈值分割的Bersen算法则非常适合处理这种情况。
OTSU算法得到的图像:
import cv2
from pylab import *
im=cv2.imread('source.png',cv2.IMREAD_GRAYSCALE)
cv2.imwrite('source.png',im)
thresh,im=cv2.threshold(im,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
cv2.imwrite('OTSU.png',im)

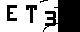
Bersen算法
原始的Bersen算法很简单,对于每一个像素点,以他为中心,取一个长宽均为((2w+1)^2)的核;对于这个核,取当中的极大值和极小值的平均值作为阈值,对该像素点进行二值化。然后将这个过程应用到整张图即可。
这个也很好理解,只要取一个适当的核的大小w,就可以在每一个局部内取得一个较好的阈值而不去考虑全局的其他像素。但是这有一个问题,就是他对噪声比较敏感,毕竟每一个像素点的取值仅仅依赖于附近区域内的极大极小两个值。因此实际操作中通常不是取极大极小值,而是取整个核的平均值或是加权平均值。具体操作下来通常就是用一个高斯平滑滤波。
实现效果
算法比较简单,而且OpenCV里直接给了个函数调用,方便省事。
import cv2
from pylab import *
%matplotlib inline
im=cv2.imread('13.png',cv2.IMREAD_GRAYSCALE)
im=cv2.adaptiveThreshold(im,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,11,2)
cv2.imwrite('mean.png',im)
im=cv2.adaptiveThreshold(im,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2)
cv2.imwrite('gaussian.png',im)
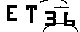
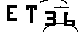
分别用平均加权和高斯加权显示。。效果差不多,都挺好的。这里的倒数第二个参数就是卷积核的大小,最后一个参数是像素的矫正,即将实际算得的像素减去这个值得到结果。