
批量梯度下降算法
这一讲介绍了我们的第一个机器学习算法,”批量“梯度下降算法(Batch Gradiant Descent)。注意到他在前面加了个“批量(Batch)”,这其实是为了与以后的另一种梯度下降算法进行区分从而体现出这个算法的特点。
线性回归
梯度下降算法这是用来解决所谓的“线性回归”问题。线性回归应该都懂了,这里大概的进行下定义(以单变量为例):
1、给你一个数据集(Training Set),数据集中有很多个数对,表示$(x_i,y_i)$。
2、你的任务是构造一个预测函数$h_\theta(x)=\theta_0+\theta_1x$,使得这个函数对于任意给定的$x$,能很好的预测出他对应的$y$。
3、为了判断预测函数的准确性,我们引入一个费用方程:
$$J(\theta_0,\theta_1)=\frac{1}{2m} \underset{i=1}{\overset{m}{\Sigma}}(h(x_i)-y_i)^2$$
这里的m表示数据集中数据的个数,x和y表示每一个数据。很明显这里用的是最常见的求平方差的二次误差函数,不过这里多引入了一个$\frac{1}{2}$,其实没有别的意思,只是为了后面求导的时候方便约掉他,从而使求导后的式子更好看。
4、我们的目标就是找到$\theta_0,\theta_1$使得J函数取最小值。
一个具体的数据
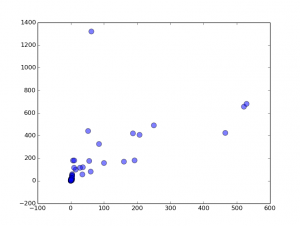
为了更加直观的表现,我在people.sc.fsu.edu 上找到了一些线性回归的数据集,用了其中的第一个来展示(去掉了一些夸张的数据):
1 3.385 44.500
2 0.480 15.500
3 1.350 8.100
4 465.000 423.000
5 36.330 119.500
6 27.660 115.000
7 14.830 98.200
8 1.040 5.500
9 4.190 58.000
10 0.425 6.400
11 0.101 4.000
12 0.920 5.700
13 1.000 6.600
14 0.005 0.140
15 0.060 1.000
16 3.500 10.800
17 2.000 12.300
18 1.700 6.300
19 4.235 50.400
20 0.023 0.300
21 187.100 419.000
22 521.000 655.000
23 0.785 3.500
24 10.000 115.000
25 3.300 25.600
26 0.200 5.000
27 1.410 17.500
28 529.000 680.000
29 207.000 406.000
30 85.000 325.000
31 0.750 12.300
32 62.000 1320.000
33 0.104 2.500
34 3.500 3.900
35 6.800 179.000
36 35.000 56.000
37 4.050 17.000
38 0.120 1.000
39 0.023 0.400
40 0.010 0.250
41 1.400 12.500
42 250.000 490.000
43 2.500 12.100
44 55.500 175.000
45 100.000 157.000
46 52.160 440.000
47 10.550 179.500
48 0.550 2.400
49 60.000 81.000
50 3.600 21.000
51 4.288 39.200
52 0.280 1.900
53 0.075 1.200
54 0.122 3.000
55 0.048 0.330
56 192.000 180.000
57 3.000 25.000
58 160.000 169.000
59 0.900 2.600
60 1.620 11.400
第一列是编号,第二列表示人脑的重量,第三列表示人身体的重量,我们用matplotlib画个图来看看:
绘图代码
import numpy as np
import theano.tensor as T
import matplotlib.pyplot as plt
file=open("data","r")
brain=[]
body=[]
for line in file:
num,_brain,_body=line.split()
brain.append(_brain)
body.append(_body)
plt.scatter(brain,body,s=100,alpha=.5)
plt.show()
ok,接下来我们就是找出符合条件的$\theta_0,\theta_1$了。
J函数
根据J函数的表达式,我们可以很容易的求出他的具体的表达式。当然,我们也可以很容易的画出他的函数图像。很明显,他的图像应该是一个三维图像(当然,如果因变量不止一个的话,得到的应该是更高维度的图像):

绘图代码
import numpy as np
import theano.tensor as T
from pylab import *
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
#read file
file=open("data","r")
brain=[]
body=[]
for line in file:
num,_brain,_body=line.split()
brain.append(_brain)
body.append(_body)
brain=np.array(brain).astype(float)
body=np.array(brain).astype(float)
#calculate p
def p(t0,t1):
sum=0
num=len(brain)
for i in range(0,num):
sum+=pow((t0+t1*brain[i]-body[i]),2)
sum/=2*num
return sum
#important values
size=20
X=np.linspace(-100,100,size)
Y=np.linspace(0,2,size)
#draw the picture
X,Y=np.meshgrid(X,Y)
X=X.reshape(size*size)
Y=Y.reshape(size*size)
Z=np.arange(0,size*size)
for i in range(0,size*size):
Z[i]=p(X[i],Y[i])
X=X.reshape(size,size)
Y=Y.reshape(size,size)
Z=Z.reshape(size,size)
fig=figure()
ax=Axes3D(fig)
ax.plot_surface(X,Y,Z,rstride=1,cstride=1,cmap=plt.cm.hot)
ax.contourf(X, Y, Z, zdir='z', offset=-2 )
plt.show()
(画图时注意设置图像的各部分参数使他的表现效果最好,语法不熟,写的蠢了)
从图中大概也能看到他的最低点啦,$\theta_0$大概是0±50,$\theta_1$大概是1±0.5(纯属目测)。
梯度下降
有了直观的感受我们就来看看对J求梯度下降的具体意义了。其实也很好理解,就是对于J函数上的某一个点,每一次迭代时都将他沿下降最快的方向走一小段距离(所谓方向,当然是要分到各个变量上面了)。这样经过一段时间,他就会接近图像的最低点了。用数学表达式来理解就是:
repeat until convergence:
$$\begin{aligned}\theta_j&:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta_0,\theta_1)\\&:=\theta_j-\frac{\alpha}{m}\underset{i=1}{\overset{m}{\Sigma}}(h(x_i)-y_i)x_i\\&(for\ j=0\ and\ j=1)\end{aligned}$$
上式兼容了多元变量的情况,事实上在本例中$x_0$显然是1,$x_1$就是数据中的x。
这里的$:=$是为了强调这是赋值操作而不是判等。
要注意的是,每一次迭代都要将每一个方向计算一次,而且要注意赋值的顺序,$\theta_j$一定要在迭代最后同时(simultaneously)用新值代替。
这里的$\alpha$又被称为”学习因子(learning rate)“,在迭代的时候要注意这个值的选取。形象的看其实就是每次下降迈的步子的大小。如果过大则会导致跨越了最低点甚至导致越走越远,如果过小则会导致迭代代价太高,运行缓慢。
当然,理论上这个算法也只能求得局部最低点,并不能保证是全局最低点。
根据这个公式,我们注意到每一次迭代都得将所有的数据用一遍,这导致了效率的低下。所以由于这个算法又被称为批量梯度下降算法(BGD)。
简单实现
参考代码
import numpy as np
import theano.tensor as T
from pylab import *
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
#read file
file=open("data","r")
brain=[]
body=[]
for line in file:
num,_brain,_body=line.split()
brain.append(_brain)
body.append(_body)
brain=np.array(brain).astype(float)
body=np.array(brain).astype(float)
def partial_t0(a,t0,t1):
sum=0
num=len(brain)
for i in range(0,num):
sum+=(t0+t1*brain[i]-body[i])
return t0-sum*a/num
def partial_t1(a,t0,t1):
sum=0
num=len(brain)
for i in range(0,num):
sum+=(t0+t1*brain[i]-body[i])*brain[i]
return t1-sum*a/num
print("%-6s%20s%20s%20s" %('alpha','theta0','theta1','times'))
for i in range(1,11):
a=pow(10,-i)
t0=0
t1=0
dt0=10000000
dt1=10000000
cnt=0
while abs(t0-dt0)+abs(t1-dt1)>0.0001:
dt0=t0
dt1=t1
t0=partial_t0(a,dt0,dt1)
t1=partial_t1(a,dt0,dt1)
cnt+=1
print("%-6s%20s%20s%20s" %(a,t0,t1,cnt))
输出
alpha theta0 theta1 times
0.1 -inf nan 96
0.01 inf nan 139
0.001 inf nan 255
0.0001 0.00310245521884 0.999954444466 26
1e-05 0.00310682944277 0.999536382475 42
1e-06 0.00309052228147 0.994195497596 305
1e-07 0.00292431336052 0.940626826916 1685
1e-08 0.00125884490338 0.40488187492 3099
1e-09 5.20663166667e-08 1.67458362859e-05 1
1e-10 5.20663166667e-09 1.67458362859e-06 1
代码比较简单,就不展开了。这次我把迭代起点选在(0,0)。需要注意的是这个结果,在$\alpha$取不同值的时候,输出的结果和性能的表现也大不相同。
1、由于我是用变化前后的差别来判断聚合程度的,所以当学习因子过小的时候会出现一次迭代就终止了,这显然不是我们想看到的结果;
2、同时,当学习因子过大的时候,会出现函数发散的现象,这显然也不是我们想要的结果;
3、在能得到正确解的学习因子里,程序的运行速度也随着因子的减小而减慢,但是准确程度也因而增加。
所以学习因子的选择至关重要。
因此最终的拟合结果就是。。。。莫急,让我们换一个迭代起点看看,这次我们选(2,2)为迭代起点(将t0和t1分别改成2),这次得到的结果是:
alpha theta0 theta1 times
0.1 inf nan 96
0.01 -inf nan 139
0.001 -inf nan 255
0.0001 1.18929235272 0.9963020556 6183
1e-05 1.99615299339 0.994173518979 43
1e-06 1.99637710179 0.999525819249 306
1e-07 1.99677269246 1.05302607963 1690
1e-08 1.99866893391 1.58880170812 3137
1e-09 1.99999994593 1.99998315003 1
1e-10 1.99999999459 1.999998315 1
卧槽,傻眼了,结果与上一个差别还是很大的,那么到底哪一个才更准确呢~~~额,,其实我也不晓得,只能说以现在的知识并不知道怎样很好的解决这个问题。我想应该是因为基于我电脑的速度,我的阈值设置的不够小,导致无论从哪个起点开始迭代最终到达的应该是一个离最优解附近的一个类圆形区域里,无法深入到内部。有一个解决方案大概就是遍历最内部的这个区域来求解吧,不过设置参数应该也是挺麻烦的,复杂度也挺大的...
最后,画一下拟合的结果(取上面提到的所有合理的值):
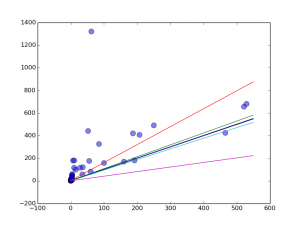
(怎么和想象中差别有点大。。。)