多变量线性回归算法
其实所谓的多变量的线性回归(Linear Regression with multiple variables )本质上将与单变量的线性回归没啥差别。因此我们完全可以用上一节中的梯度下降算法来解决,只需要在每一次迭代的时候多考虑几个变量而已。所以这一节就稍微介绍一下了,不再用例子分析。不过毕竟多了一些变量,在对多变量跑梯度下降算法时,显然对参数的调节就更加重要了,因此我们首先得学会一些参数调节的技巧。这些技巧在实际的操作过程中尤为重要。
调节参数
特征值缩放(Feature Scaling)
我们知道在进行梯度下降算法时,经常会有这样一个问题,就是如果两个特征变量$x_i$和$x_j$的范围差别很大,那么每一次迭代时,他们下降的相对速率就不一样,这就直接导致了范围大的那个变量下降的过慢。为了解决这个问题,我们引入了特征值缩放这个技巧。其实也很简单,就是把每一个参数的变化范围大概控制在一起,这样他们的下降速率就不会受到相互的牵连。具体的操作就是将他所有参数的值,都缩放在大小差不多的一个区域内(通常是(-1,1))。为了进行这样的缩放,我们就需要接下来的方法。
标准化(Mean Normalization)
为了缩放到一个区域((-1,1))内,我们要做两件事:第一,把平均值对应到0点;第二,把最大最小值对应到-1和1这两点。想想也很好理解,用公式表示就是:
$$x_i:=\frac{x_i-u}{2\sigma}$$
这里的$x_i$表示需要标准化的数据,$u$表示在数据集中这种参数的平均值,$\sigma$表示数据集中这种参数的标准差。看着很眼瘦?没错,这个就是我们求正态分布的那个标准化转换函数。
经过这样的转换,每一个变量都会将他的值缩放到(-1,1)中了,进而方便我们进行梯度下降。
学习因子$\alpha$的选取
我们知道学习因子既不能过大也不能过小。实际上,对于一个学习因子是好是坏我们可以这样判断。对于一个特定的学习因子$\alpha$,我们可以画出J函数与迭代次数的关系图。对于一个好的$\alpha$,他的函数图像应该是一个类似$y=\frac1x$的图像。如果J函数下降的速度过慢,显然我们需要增加学习因子使他下降的更快;如果J函数是增函数,或者在某些区间内有上升的趋势,那么显然我们需要减小学习因子防止学习过度。
多项式回归(Polynomial Regression )
对于某些不能用线性回归的问题,我们有时候可以试着用多项式来进行回归拟合。其实多项式回归完全可以看成是多变量的线性回归问题,因为我们完全可以把其中的$x^i$看成是第$i$个独立的变量,只不过他的值是由$x$推出来的而已。原理很简单,但是如果想不到那就头大了0.0。
公式法(Normal equation)
介绍
对于多变量的线性回归,除了用我们之前学的GD算法,我们其实还有另外一个直接套公式的算法(卧槽早说)。这牵涉到线性代数的知识,我们需要做的只是将数据集组合成几个矩阵,然后运算一个公式即可,这个公式就叫 Normal equation (觉得叫成“正规方程”好难听):
$$\theta=(X^TX)^{-1}X^Ty$$
其实这个方法就是矩阵最小二乘法了。
其中$X^T$表示$X$的转置,$X^{-1}$表示$X$的逆。
这个公式,得到的结果就是对整个数据集最好的线性逼近。下面介绍下这个公式怎么用。
用法
假设我们的数据集有m个数据,我们的变量有n个(即每一个数据有n个特征值),那么我们可以把所有的输入数据写成一个m*(n+1)的矩阵。为什么是n+1列,因为我们知道,对n个参数的回归需要用到n+1个$\theta$。只是这当中的$\theta_0$一直取1罢了。因此这个矩阵的第一列全部都是1。
上面的这个矩阵,就是我们公式中的X了。
对于公式中的$y$,其实是由所有的输出数据组成的列向量,与输入一一对应。
最后,我们只需要计算上面这个公式的结果就能计算出$\theta$向量的值了,(很明显这个向量应该是一个n+1维的列向量)
至于这个公式的证明。。。貌似很麻烦,百度normal equation 可以找到需要的证明过程。
说明
这里有一个问题,就是如果$X^TX$没有逆元怎么办?
事实上正常情况下是不会没有逆元的,没有逆元的情况一般有两种:
1、参数中有线性相关的两组量。比如一个参数是用厘米表示的高度,另一个参数是用米表示的同样的那个高度。显然,这样选择参数是没有意义的,对于这种情况我们只要删掉其中一个参数就好了。
2、数据集的数量m小于参数的个数n。通常情况下当然是不会发生这种事的,毕竟都没几个数据还怎么好意思来拟合?不过万一出现这种状况,也是有对应的办法的,这种情况以后再说。
性能
我们注意到这里需要求矩阵的逆,而$X^TX$是一个n*n的矩阵,因此他的复杂度通常至少是$O(n^3)$(虽然可以优化,但是也差不多这么大)。这在n比较小的时候效果还挺不错的,而且比GD算法更加方便准确。但是当参数的个数变多了的时候,效率就会特别慢,相比之下GD算法的优势就显现出来了。
实现
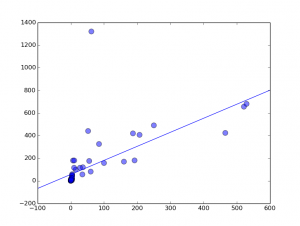
接下来我就结合上一节的例子试着实现一下,虽然是单变量,但是道理是一样的。
import numpy as np
import theano.tensor as T
from pylab import *
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
#read file
file=open("data","r")
brain=[]
body=[]
for line in file:
num,_brain,_body=line.split()
brain.append(_brain)
body.append(_body)
#calculate
size=len(brain)
X=np.matrix(np.vstack((np.ones(size),brain))).reshape(2,size).T.astype(np.float)
Y=np.matrix(body).T.astype(np.float)
out=(X.T*X).I*X.T*Y
print out
#draw
out=np.array(out)
px=np.linspace(-100,600,100)
py=px*out[1]+out[0]
plt.plot(px,py)
plt.scatter(brain,body,s=100,alpha=.5)
plt.xlim(-100,600)
plt.ylim(-200,1400)
plt.show()
(这里写代码的时候要非常注意np.matrix的用法以及强制指定数据类型)
最后算得:$\theta_0=55.95185719,\theta_1=1.24271276$,从图上看还是拟合的挺不错的。