
逻辑回归算法
说到逻辑回归(Logistic Regression),其实他解决的并不是回归问题(Regression),而是分类问题(Classification)。分类问题都明白了,他和一般的回归问题的差别其实也就在于一个值域是连续的,而另一个值域是离散的,
Sigmoid函数
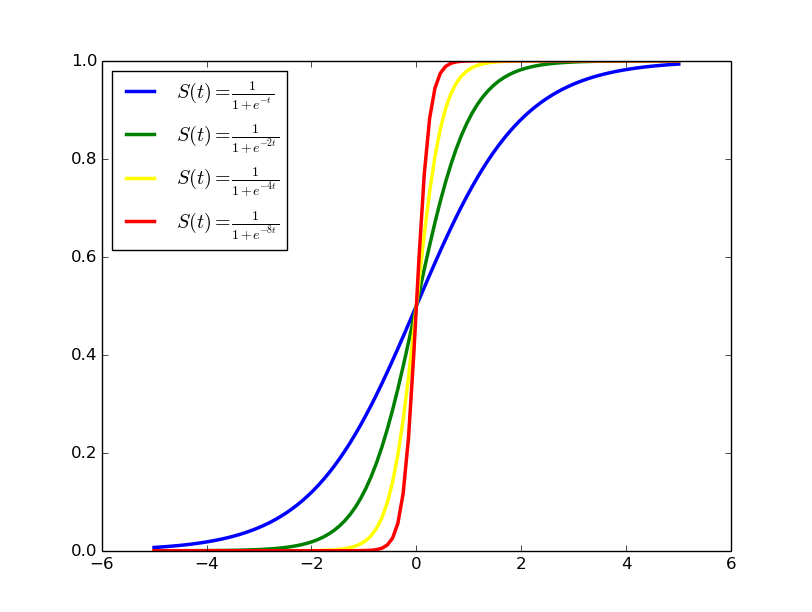
我们都知道分类问题需要解决的问题是给你一个分好类的训练集,然后给你一个数据让你判断这个数据属于哪一类。严格来说这是一个离散的问题,然而我们一般能够处理的都应该是连续可导的函数。而连续可导的线性函数一般都不能非常好的体现出离散的特征。这时候我们就需要一个特殊的函数来近似的处理离散的分类问题,这就引入了我们著名的逻辑函数(Logistic Function),又称Sigmoid函数:$$S(t)=\frac{1}{1+e^{-\theta t}}$$
import numpy as np
from matplotlib.pylab import *
x=np.linspace(-5,5,100)
y=1/(1+np.exp(-x))
plot(x,y,color='blue', linewidth=2.5,label='$S(t)=\\\\frac{1}{1+e^{-t}}$')
y=1/(1+np.exp(-2*x))
plot(x,y,color='green', linewidth=2.5,label='$S(t)=\\\\frac{1}{1+e^{-2t}}$')
y=1/(1+np.exp(-4*x))
plot(x,y,color='yellow', linewidth=2.5,label='$S(t)=\\\\frac{1}{1+e^{-4t}}$')
y=1/(1+np.exp(-8*x))
plot(x,y,color='red', linewidth=2.5,label='$S(t)=\\\\frac{1}{1+e^{-8t}}$')
legend(loc='upper left')
show()
我们可以看到随着$t$的值逐渐远离原点,函数值迅速的向0或者1无限逼近,非常好的模拟了一个离散的效果,而且随着\theta值的增大,逼近的趋势也更加明显。这就很好的满足了我们的要求。
有了这个函数,我们就可以试着用他来拟合一些分类的问题。为了简单起见,我们先讨论二值分类的问题。
决策边界(Decision Boundary)
使用了逻辑函数作为拟合函数后,我们就可以写出我们的预测函数了:$$h_\theta(x)=S(\theta^Tx)$$S函数里面的其实就是一个线性方程,很明显,这个线性方程大于0的时候,输出的结果就是1,小于0的时候输出的结果就是0。也就是说,这个线性方程的解就是我们做出决策的边界了。
当然,这个边界完全可以不用是线性方程。比如,我们完全可以通过构造一些高阶的参数来使决策边界呈现一个圆:
$$\theta^Tx=\theta_0+\theta_1x_1^2+\theta_2x_2^2$$
由此,理论上我们就可以构造任何形状的决策边界来拟合各种各样的分类问题。
代价函数(Cost Function)
在之前介绍线性回归的函数时,我们在比较预测的函数和数据集的匹配程度的时候用到了$\frac12 (h_\theta(x_i)-y_i)^2$这个东西。这个其实就是一个代价函数或者叫损失函数(Loss Function)(具体一点,这其实叫做平方损失函数),即相似程度越不好,那么这个使用这个函数的代价就越大,就越不建议使用他。于是我们完全可以用这个函数作为比较拟合程度的依据,而后对数据集中的所有数据的代价求和,就是我们总的代价,也就是之前的J函数。
综上,我们可以先定义线性回归中的Cost Function:
$$Cost(h_\theta(x),y)=\frac12(h_\theta(x)-y)^2$$
与之前不同,对于逻辑回归,现在我们的$h(x)$不再是一个线性方程了。很明显,对这个函数如果用平方损失函数来算的话,对后续的求导求和等运算会带来极大的不便。而且更重要的是,他并不是一个下凸函数,所以甚至不能用GD算法求极值。因此我们将他的Cost Function定义为下式:
$$
Cost(h_\theta(x),y)=\left\{\begin{aligned}-log(h_\theta(x))\ if\ y=1&\\-log(1-h_\theta(x))\ if\ y=0 & \end{aligned}\right.
$$
当然,如果想把分类函数合并下也可以得到下面的形式:
$$Cost(h_\theta(x),y)=-ylog(h_\theta(x))-(1-y)log(1-h_\theta(x))$$
对于这个方程,我们要看到,当$h_\theta(x)$与$y$相差很大的时候,他的代价甚至可以趋近去正无穷!而且,这个函数可以非常方便的求导数,也可以非常方便的对$\theta$求偏导。这样的代价方程以后也会经常用到,他又叫对数损失函数。
梯度下降
有了损失函数,我们就可以构造用于梯度下降的J函数了。实际上就是对每一个代价求和就行了:
$$J(\theta)=\frac{1}{m}\underset{i=1}{\overset{m}{\Sigma}}Cost(h_\theta(x_i),y_i)$$
进而,我们对J函数中每一个\theta求偏导,可以得到下面的梯度下降算法:
repeat until convergence:
$$\begin{aligned}\theta_j&:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta)\\&:=\theta_j-\alpha \underset{i=1}{\overset{m}{\Sigma}}(h_\theta(x_i)-y_i)x_{i,j}\\\end{aligned}$$
simultaneously update all $\theta_j$
这里有$h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}$,而$x_i$对应的是每一组数据构成的列向量,$x_{i,j}$表示第i组数据的第j个值。
没错,最终的表达式跟线性回归的计算方法几乎一模一样(注意少了一个分母上的m)!这就是Sigmoid函数的强大之处。
优化算法
对于逻辑回归算法,有一些高级的优化算法比如Conjugate gradient、BFGS、L-BFGS等,这些跑起来快,但是难学。。。这里就不提了。
多元分类问题
有了二元的分类问题,很自然我们就会想到多元的分类问题。对于多元的分类问题,我们的处理方法其实很朴素,就是把一个n元的分类问题转化为n个二元的分类问题,又叫”One-vs-All“。意思已经很清楚了,照着二元的分类问题弄n次就好了。